While waiting for the computer parts to arrive I am thinking about the right Linux distribution for a deep learning server. Visiting the official Nvidia system requirements for CUDA on Linux web page they only support RHEL, CentOS, Fedora, SUSE and Ubuntu. I personally used Suse, RedHat and Debian before, and currently my sympathies are with Debian (great community, good packet manager and repository, reasonable update intervals, a reliable distribution and completely open).
However, CentOS is an alternative being the community version of RedHat, and it seems to be just as stable and reliable. On the other hand, the update intervals are very long (the last major release was 5 years ago), and there seems to be less of a community compared to Debian.
Ubuntu is currently the most popular distribution, but somewhat more for desktop use. Also, I don’t like the profit orientation of Canonical, the company behind Ubuntu. A plus is, that it is a derivative from Debian with the same package system that I like.
With Fedora I am missing the long-term support (only 13 month). And my personal perception is that it is somewhat on the descending branch.
SUSE had it’s strong days 20 years ago and has for sure the smallest community of all mentioned.
Trying to consider facts I looked at Google Trends on how many search requests have been started for the different distributions in combination with CUDA:
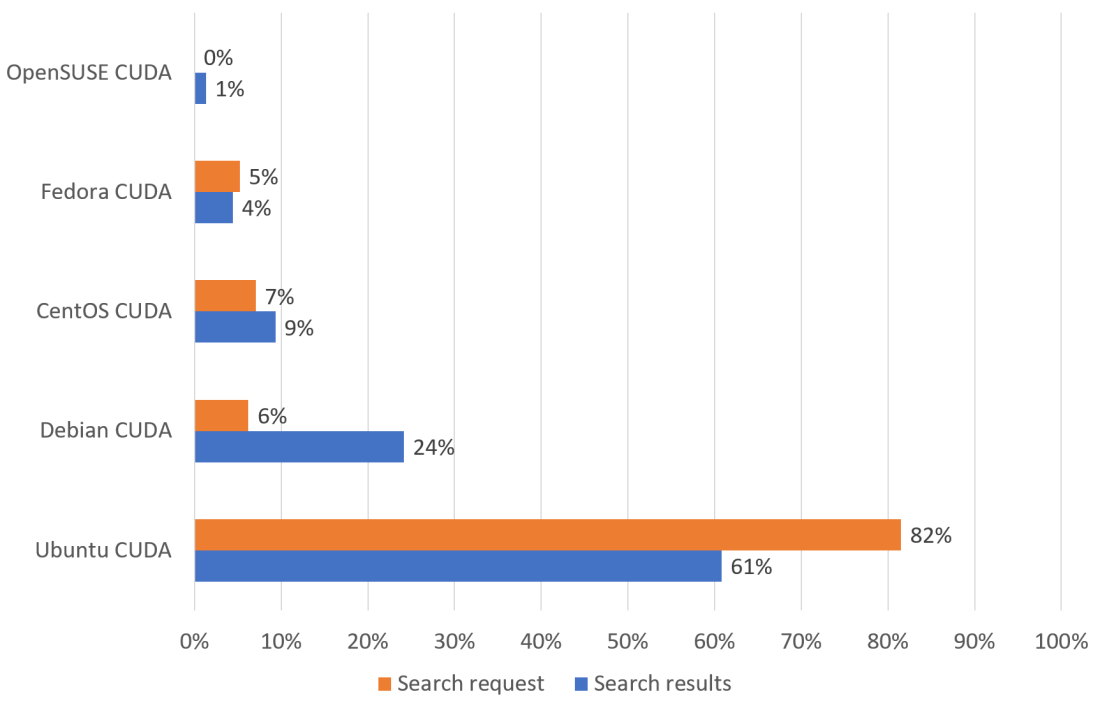
Ubuntu comes out first by more than a factor of 10, followed by Debian and CentOS. But this only means, that many Ubuntu users look for help on CUDA, which could also be caused by CUDA not being easy to get to run with Ubuntu or the Ubuntu users being less experienced with Linux. So, I did also look at how much hits, i.e. answers a similar Google search results in. Again, Ubuntu is first but only by factor 2.5. Debian is again second, in front of CentOS by another factor 2.5. Interesting that the only by Nvidia not supported distribution Debian comes out so strong.
A good insight on CUDA, as CUDA is a must have for Deep Learning nowadays, but finally I want to program with Keras. So, I did the same for Keras in combination with the distribution:
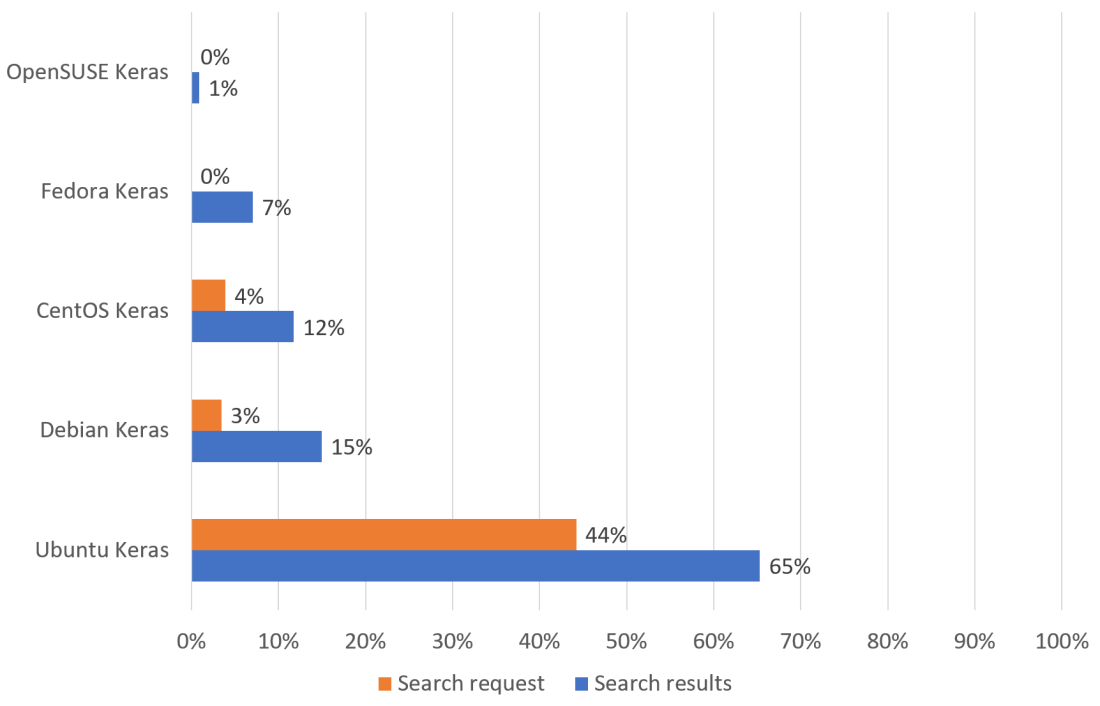
A similar picture: Ubuntu clearly first, Debian second but closer followed by CentOS. So rationally everything speaks for Ubuntu. But my heart beats for the open and reliable Debian, being the number two and the ancestor of Ubuntu. Not supported by Nvidia, but I will give it a try!